是否要将PDF文档或图像转换为文本?最近,有人通过邮件向我发送了一份文件,我需要编辑并发回更正。这个人无法找到数字副本,所以我的任务是将所有文本都变成数字格式。
我没办法花几个小时输入所有内容,所以我最终服用了一个很好的高质量的文档图片,然后通过一堆在线OCR服务烧掉我的方式,看看哪一个会给我最好的结果。
在这篇文章中,我将通过一对夫妇我最喜欢的免费OCR网站。值得注意的是,大多数这些网站提供基本的免费服务,如果你想要更大的图像,多页PDF文档,不同的输入语言等额外功能,那么付费选项。
它也很好事先知道大多数这些服务都无法匹配原始文档的格式。这些主要用于提取文本,就是这样。如果您需要特定布局或格式的所有内容,则必须在从OCR获取所有文本后手动执行此操作。
此外,获取文本的最佳结果将会到来来自200到400 DPI分辨率的文档。如果您的DPI图像较低,结果将不会很好。
最后,我测试的很多网站都没有用。如果你谷歌免费在线OCR,你会看到一堆网站,但前十名结果中的几个网站甚至没有完成转换。有些人会超时,有些会出错,有些人只是卡在“转换”页面上,所以我甚至懒得提这些网站。
对于每个网站,我测试了两个文件看输出效果如何。对于我的测试,我只是使用我的iPhone 5S拍摄两个文档的照片,然后将它们直接上传到网站进行转换。
如果你想看看我用过的图像是什么样的我的测试,我在这里附上了它们:测试1 和TEST2 。请注意,这些不是从手机拍摄的图像的完整分辨率版本。我在上传到网站时使用了全分辨率图像。
{kind=link}
{kind=link}
OnlineOCR
OnlineOCR.net 是一个干净简单的网站,在我的测试中取得了非常好的效果。我最喜欢的是它在整个地方都没有大量的广告,这种情况通常都适用于这些小众服务网站。

要开始,请选择您的文件并等到完成上传。此站点的最大上载大小为100 MB。如果您注册一个免费帐户,您将获得一些额外的功能,如更大的上传大小,多页PDF,不同的输入语言,每小时更多的转换等。
接下来,选择您的输入语言和然后选择输出格式。您可以选择Word,Excel或纯文本。点击转换按钮,您会在框中看到底部显示的文字以及下载链接。
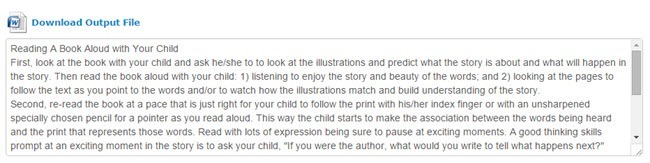
如果你想要的只是文字,只需从框中复制并粘贴即可。但是,我建议您下载Word文档,因为它在保持原始文档的布局方面做得非常出色。
例如,当我打开Word文档进行第二次测试时,我很惊讶发现该文档包含一个包含三列的表格,就像在图像中一样。
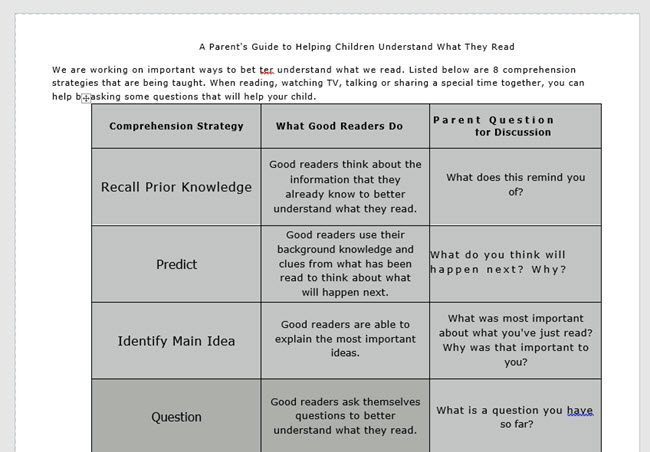
在所有网站中,这一个是最好的到目前为止。如果您需要进行大量转换,那么完全值得注册。
为了完整性,我还要链接到每个服务创建的输出文件,以便您自己查看结果。以下是OnlineOCR的结果:Test1 Doc 和Test2 Doc 。
请注意,在计算机上打开这些Word文档时,您会收到一条消息Word声明它来自互联网并且编辑已被禁用。这是完全正常的,因为Word不信任来自互联网的文档,如果你只是想查看文档,你真的不需要启用编辑。
i2OCR
另一个网站得到了相当不错的结果是i2OCR 。过程非常相似:选择您的语言,文件,然后按提取文字。
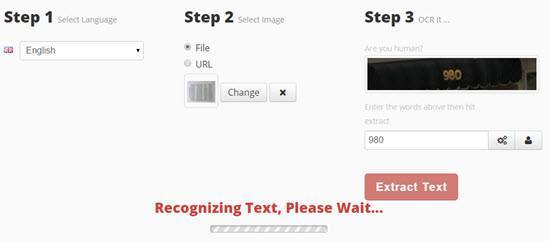
您将这里需要等一两分钟,因为这个网站需要更长的时间。此外,在第2步中,确保您的图像在预览中正面显示,否则您将获得一堆乱码作为输出。出于某种原因,我的iPhone上的图像在我的计算机上以纵向模式显示,但在我上传到此网站时仍然是风景。

I必须在照片编辑应用程序中手动打开图像,将其旋转90度,然后将其旋转回肖像,然后再次保存。完成后,向下滚动,它会显示文本的预览以及下载按钮。
这个网站在第一次测试时输出效果非常好,但是没有做得很好具有列布局的第二个测试。以下是i2OCR的结果:Test1 Doc 和Test2 Doc 。
{kind=link}
{kind=link}
FreeOCR
Free-OCR.com 将采取您的图像并将其转换为纯文本。它没有导出为Word格式的选项。选择您的文件,选择一种语言,然后点击开始。
网站速度很快,您可以相当快地获得输出。只需点击链接即可将文本文件下载到您的计算机上。
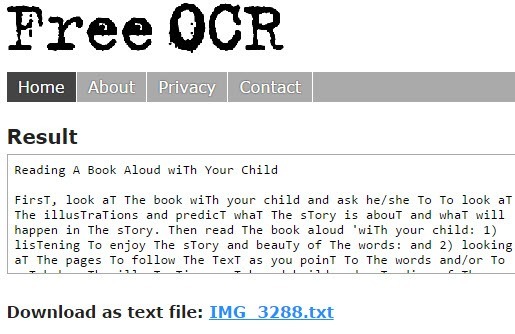
与下面提到的NewOCR一样,本网站将所有T的资本化为该文件。我不知道为什么会这样做,但由于一些奇怪的原因,这个网站和NewOCR都这样做了。改变它并不是什么大不了的事,但这是一个你真的不应该做的繁琐的过程。
以下是FreeOCR的结果:Test1 Doc 和Test2 Doc 。
ABBYY FineReader Online
要使用FineReader Online ,您必须注册一个帐户,这会让您获得15天免费试用OCR最多10页免费。如果您只需要为几页进行一次性OCR,那么您可以使用此服务。注册后,请确保单击确认电子邮件中的验证链接。
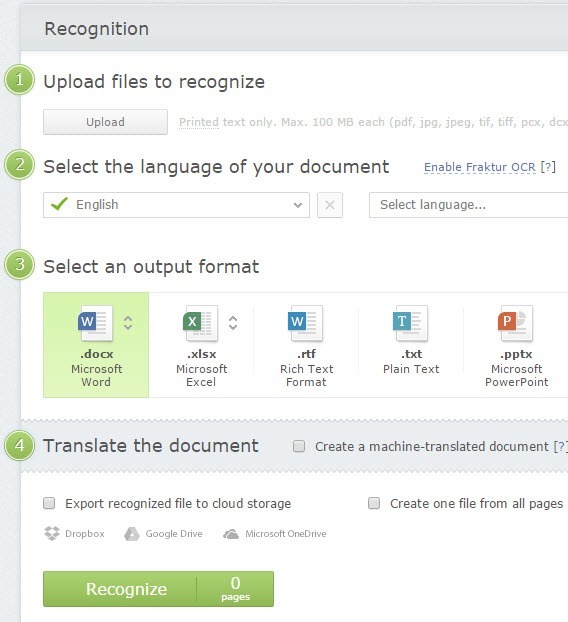
点击顶部的识别,然后点击上传以选择您的文件。选择您的语言,输出格式,然后点击底部的识别。这个网站有一个干净的界面,也没有广告。
在我的测试中,这个网站能够从第一个测试文档中获取文本,但是当我打开Word文档时它绝对是巨大的,所以我最后再做一遍并选择纯文本作为输出格式。
对于第二次测试列,Word文档是空的,我甚至找不到文本。不确定那里发生了什么,但似乎除了简单的段落之外似乎无法处理任何事情。以下是FineReader的结果:Test1的文件 和Test2 Doc 。
NewOCR
下一个网站,NewOCR.com ,没问题,但不如第一个网站好。首先,它有广告,但幸好不是很多。首先选择文件,然后单击预览按钮。
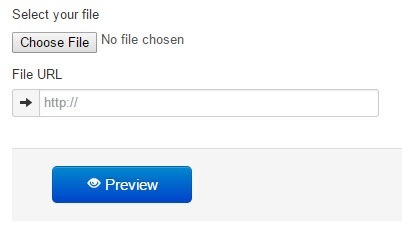
然后您可以旋转图像并调整要扫描文本的区域。这有点像扫描过程如何在带有扫描仪的计算机上运行。

如果文档有多列,你可以检查页面布局分析按钮,它会尝试将文本拆分为列。单击OCR按钮,等待几秒钟以完成它,然后在页面刷新时向下滚动到底部。
在第一个测试中,它正确地获取了所有文本,但由于某种原因,每个都大写T在文件中!不知道为什么会这样做,但确实如此。在启用页面分析的第二个测试中,它获得了大部分文本,但布局完全关闭。
以下是NewOCR的结果:Test1 Doc 和Test2 Doc 。
结论
正如您所看到的,不幸的是,free并不能在大多数情况下给您带来非常好的结果。到目前为止提到的第一个网站是最好的,因为它不仅能够很好地识别所有文本,而且还设法保留原始文档的格式。
如果你只需要文本, ,上面的大多数网站应该能够为你做到这一点。如果您有任何疑问,请随时发表评论。享受!